
1. Introduction
기존 LLM은 RLHF(Reinforcement Learning from Human Feedback)을 통해 성능을 향상시켜왔다. 사람의 선호도, 피드백을 통해 강화학습을 해온 것이다. 강화학습 알고리즘 중에도 기존에는 PPO를 사용하여 reward 모델이 필요했었으나, 최근에는 DPO를 이용하여 reward 모델도 필요 없이 human preferences를 직접적으로 이용할 수 있게 되고 있다. 본 연구에서는 인간에 의해 병목 현상이 발생할 수 있는 RLHF 대신, reward model과 LLM을 하나의 모델이 할 수 있도록 하는 방법을 연구했다.
본 연구에서 소개하는 Self-Rewarding Language Model은 다음과 같다.

step 1: Self-Instruction creation: 프롬프트가 생성되어 t 시간의 모델 M_t에서 새로운 응답 N개를 생성한다. 이 응답이 또다시 동일한 모델 M_t로 들어가서, 각 N개의 응답에 대해 reward를 생성한다. 이 reward를 바탕으로 선호도 쌍 데이터({입력, 최대 reward를 받은 답변, 최소 reward를 받은 답변})를 정리하여 DPO 학습을 통해 모델을 학습시켜 M_{t+1}을 만든다. 이 과정이 하나의 iteration이고 학습을 반복하여 모델을 완성한다. 본 논문에서는 Llama 2 70B 모델을 seed model로 사용하여 실험을 진행했다.
2. Self-Rewarding Language Models
2.1. Initialization
Seed instruction following data: (instruction prompt, response) 데이터를 준비하고, seed model에 SFT(supervised fine-tuning)을 진행한다. 이 데이터는 IFT(Instruction Fine-Tuning) 데이터라고 부른다.
Seed LLM-as-a-Judge instruction following data: (evaluation instruction prompt, evaluation result response) 데이터를 준비한다. 이 데이터에서 evaluation instruction prompt는 주어진 응답을 모델이 평가할 수 있도록 물어보고(ask), 제공되는 evaluation result response는 chain-of-thought 추론과 최종 점수(5개 중 하나 - relevance, coverage, usefulness, clarity and expertise)로 구성된다. 이 데이터는 EFT(Evaluation Fine-Tuning) 데이터라고 부른다.

실제 evaluation instruction prompt의 예시이다. 실제로 굉장히 구체적으로 주어진 response를 평가하여 점수를 계산하도록 프롬프트가 작성되어 있다.
2.2. Self-Instruction Creation
모델 훈련용 IFT, EFT를 자동으로 생성하는 작업을 수행했다.
1. Generate a new prompt: IFT에서의 프롬프트 x_i를 few-shot prompting을 이용하여 기존 seed IFT data로부터 샘플링을 하여 생성한다.
2. Generate candidate responses: LLM 모델을 통해 각각의 프롬프트 x_i로부터 N개의 candidate response {y_i^1, ... , y_i^N}을 생성한다.
3. Evaluate candidate responses: 동일한 LLM 모델을 통해 각각의 candidate response에 대해 평가하여 스코어 r을 계산할 수 있는 프롬프트를 생성했다.
2.3. Instruction Following Training
2.2.를 통해 직접 AI Feedback Training(AIFT) 데이터를 생성하였다. 이 과정에서 preference pairs 데이터를 샘플링했는데, (instruction prompt x_i, winning response y_i^w, losing response y_i^l)를 정리했다. 입력 프롬프트, 가장 점수가 높은 응답, 가장 점수가 낮은 응답을 정리한 것이다.
2.4. Overall Self-Alignment Algorithm
최종적으로 AIFT를 위해 self-alignment를 하는 알고리즘은 다음과 같다.
Iterative Training: M_1, M_2, ... M_T의 시간 순서를 갖춘 모델을 훈련시킨다. 이때, M_t는 M_(t-1)가 만들고 증가시킨 training data로 학습한다.
Model Sequence: 일부 순서에 따른 모델을 정리하면 다음과 같다.
M0: 파인튜닝이 되지 않은 기존 사전학습된 LLM
M1: M0로 초기화된 후, IFT+EFT 데이터로 SFT를 통해 파인튜닝된 모델
M2: M1으로 초기화된 후, M1으로부터 DPO를 사용하여 AIFT된 모델
M3: M2로 초기화된 후, M2으로부터 DPO를 사용하여 AIFT된 모델
3. Experiments
3.1. Experimental Setup
3.1.1. Seed Training Data
IFT Seed data: Open Assistant dataset에서 제공하는 데이터를 이용했다. 3200개의 예시 데이터를 이용했으며, 영어로 된 첫 번째 회화 턴만 샘플링한다. 사람이 주석을 단 순위(가장 높은 순위 0만 선택)에 따라 데이터를 선택했다.
EFT Seed data: 마찬가지로 Open Assistant dataset 데이터는 프롬프트별 사람의 평가 결과 데이터를 제공하는데, 이 데이터를 활용한다. 또한, 2.1.의 사진처럼 평가를 요구하는 프롬프트를 점수 기준과 함께 SFT 파인튜닝을 통해 생성한 뒤, 이렇게 생성한 프롬프트로 평가한 결과가 실제 사람의 평가 결과와 일치할 경우 training set에 그 프롬프트와 결과를 추가한다. IFT 데이터와 중복되지 않도록 1,630개의 훈련 데이터셋과 531개의 평가 예제를 만들었다.
3.1.2. Evaluation Metrics
본 self-rewarding 모델의 평가는 instruction 프롬프트를 따르는 능력, response를 평가하는 능력(reward model) 이렇게 두 가지 측면에서 이루어졌다.
Instruction Following: 256개의 테스트 프롬프트(IFT 테스트 데이터)를 이용하여, AlpacaEval evaluation prompt와 GPT-4를 이용하여 평가를 진행했다. 개발한 모델과 기존의 여러 모델들 간의 대결을 통해 승/패/무승부로 평가를 진행했는데, 특정 테스트 프롬프트에 대해 개발한 모델의 응답부터 GPT-4에게 주고, 이후에 비교 대상이 되는 모델의 응답을 주었을 때의 AlpacaEval evaluation prompt 실행 결과와, 비교 대상이 되는 모델의 응답을 먼저 GPT-4에게 주고, 이후에 개발한 모델의 응답을 주었을 때의 AlpacaEval evaluation prompt 실행 결과를 모두 고려해서, 그 결과 더 평가가 좋은 모델의 승리로 처리했고, 만약 두 경우의 결과가 다르다면 무승부로 처리했다. 또한, 805개의 프롬프트로 평가되고 GPT-4 Turbo 모델과 대결하여 GPT-4가 승률을 평가하는 방식인 AlpacaEval 2.0 leaderboard 포맷으로도 평가를 진행했다. 이뿐 아니라, 수학, 코딩, 역할극, 작문 등 다양한 범위의 도전적인 멀티턴(대화 맥락에 의존하여 답을 찾는 것) 문제 셋인 MT-Bench에 대해 개발한 모델의 응답을 GPT-4가 10점 만점으로 평가한 결과도 기록했다. 마지막으로, 9개의 NLP 평가 기준(ARC-Easy, ARC-Challenge, HellaSwag, SIQA, PIQA, GSM8K, MMLU, OBQA, NQ)로도 모델을 테스트해보았다.
Reward Modeling: Open Assistant dataset의 사람의 ranking 데이터를 활용하여 평가했다. 데이터셋의 각각의 instruction은 평균 2.85개의 응답을 가지고 있었는데, 이 응답 중 2개씩 골라서 짝을 이뤄 human ranking과 model's evaluation을 비교했다(pairwise accuracy). 또한 human ranking 순서와 model이 평가하나 ranking이 정확히 같은 개수를 센 exact match count도 평가했으며, Spearman 상관계수와 Kendall’s τ(-1~1 사이의, 1에 가까울수록 양의 관계, -1에 가까울수록 음의 관계를 가짐을 보여주는 두 지표)를 활용하여 결과를 정리했다. 마지막으로, 모델이 만점(5/5)을 준 정답이 human ranking에서도 가장 높은 위치일 때의 빈도를 측정했다.
3.1.3. Training Details
Instruction following training: SFT 파인튜닝을 진행할 때, 학습률은 5.5 * 10^(-6)에서 학습이 끝날 때에는 1.1 * 10^(-6)으로 감소하도록 코사인 함수를 사용하여 설정했다. 배치 사이즈는 16으로, dropout은 0.1로(드롭아웃될 확률: 10%) 설정했다. loss를 계산할 때는 전체 시퀀스를 타겟으로 하지 않고, 각 토큰별로 시퀀스에서 다음 토큰을 타겟으로 하여 계산하였다. DPO에서는 10^(-6)에서 10^(-7)로 감소하는 학습률을 사용하였고, 배치 사이즈는 16, 드롭아웃은 0.1, β값은 0.1로 설정했다. 학습 과정에서 200 step마다 checkpoint를 기록하고, 각 checkpoint에서 Claude 2 모델을 이용하여 생성한 결과를 253개의 validation example에 대해 평가하여 early stopping을 활용했다.
Self-Instruction creation: LLM을 이용하여 새로운 프롬프트 데이터를 생성하기 위해. Llama 2-Chat 70B 모델에 8샷 프롬프팅(8개의 예시 프롬프트로 프롬프트 엔지니어링)을 적용했다. IFT 데이터로부터 6개의, 모델이 생성한 데이터로부터 2개의 데모를 가져와 샘플로 이용한다. 디코딩 파라미터로는 T(temperature) = 0.6, p = 0.9(Top-p sampling; p=0.9는 매우 다양한 데이터를 샘플링하는 것임)를 이용했다. 프롬프트 생성 파트를 제외하고 응답 생성 및 평가 등 다른 부분에서는 학습 중인 self-rewarding 모델을 이용했다. candidate response 생성의 경우 N = 4(4개)의 응답을 생성하고 T = 0.7, p = 0.9로 생성한다. candidate response를 평가할 때, 각 점수에 분산이 있으므로 디코딩 파라미터를 고정해준 뒤 3번 평가를 시행하여 평균값으로 점수를 설정한다. 이 방법으로 선호도 쌍을 M1를 이용한 M2의 AIFT 데이터셋에서는 3,964개, M2를 이용한 M3의 AIFT 데이터셋에는 6,942개를 생성해서 추가했다.
3.2. Results
3.2.1. Instruction Following Ability

먼저 첫 번째 그래프를 보자. IFT 혼자로만 파인튜닝한 SFT Baseline과 EFT+IFT로 파인튜닝한 M1의 경우 성능이 비슷했다. 이 결과는 모델의 self-reward 능력 향상이 그 모델의 다른 스킬에는 영향을 미치지 않음을 증명하는 결과이다. 계속해서 그래프에서 볼 수 있듯이, M2, M3으로 iteration이 지나며 모델이 학습될수록 모델의 성능이 향상되고 있다. 두 번째 그래프에서도 M3가 M2, M1에 비해 성능이 높다는 것을 확인할 수 있다.
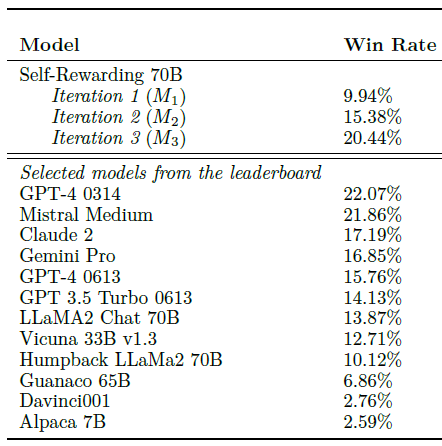
AlpacaEval 2 leaderboard 결과 표이다. M1, M2, M3로 갈수록 승률이 증가하고 있으며, 이 M3는 GPT-4(0314)와 얼추 비슷한 성능을 보인다. 본 연구에서 개발한 모델과 경쟁 상대로 나열된 모델들은 대부분 독점적인 많은 양의 데이터(ex: 주석이 1M개)를 사용하나, 본 연구에서 개발한 모델은 Open Assistant의 작은 시드 데이터에서 시작했다는 점에서 이 결과는 큰 의미가 있다.
이외의 결과 지표들은 직접 논문에서 찾아 보길 바란다.
3.2.2. Reward Modeling Ability

위 표에서 볼 수 있듯이, IFT만으로만 응답을 평가하는 것보다, EFT를 추가한 것이 더 Reward Model로서의 성능이 높은 것을 알 수 있다. 또한, 학습을 진행할수록 더 성능이 좋아지는 모습도 확인할 수 있다.
'논문 리뷰' 카테고리의 다른 글
| NExT-GPT: Any-to-Any Multimodal LLM by NExT++ Lab of <National University of Singapore> (3) | 2024.09.01 |
|---|---|
| LARGE LANGUAGE MODELS AS OPTIMIZERS by Google DeepMind (6) | 2024.09.01 |

