
1. Introduction
우리의 세계는 본질적으로 multimodel이다. 사람들이 다른 감각 기관을 통해 이미지, 언어, 비디오, 소리 등을 인지하기 때문이다. 따라서 사람을 모방하기 위한 any-to-any 모델을 만들기 위한 노력이 계속되어왔고, 본 연구에서는 이전까지의 한계를 보완하기 위한 모델로 NExT-GPT를 제안한다. 이는 any-to-any MM-LLM으로 텍스트, 이미지, 비디오, 오디오 이 네 개의 방식 중 어느 조합으로도 input과 output을 다룰 수 있다. 아래 사진은 이 모델의 구조로, 세 개의 계층으로 구성된다.

첫 번째 계층에서는 다양한 방식의 인풋을 받는 인코드를 배열한다. 이 인코더는 LLM이 이해할 수 있는 언어와 유사한 표현을 출력한다. 두 번째 계층에서는 이미 존재하는 오픈 소스 LLM을 활용하여, 정보를 이해하고 추론할 수 있도록 한다. 이 LLM은 text 토큰을 직접적으로 만들 뿐 아니라 'modality signal' 토큰을 만들어서 디코딩 층에서 받아서 변환할 수 있도록 한다. 세 번재 계층에서는 각각 다른 인코더들로부터 온 생성된 multimodel signal들이 대응되는 방식에 따라 content로 생성된다. 이때 인코더와 디코더로는 새로 모델을 만들지 않고 고성능의 사전 학습된 CLIP, ImageBind, state-of-the-art latent diffusion models 등을 이용한다. 이 모델들의 가중치는 학습하지 않고 동결시킨다. 이 선택으로 cold-starting 문제도 방지한다. 또한 MosIT 데이터셋을 이용하고 LoRA 테크닉을 적용하여 전반적인 NExT-GPT 모델을 파인튜닝 시킨다.
2. Related Work
관련 사전 연구로는 다음과 같은 주제로 연구한 것들이 있다.
- Cross-modal Understanding and Generation
- Multimodal Large Language Models
3. Overall Architecture
- Multimodal Encoding Stage: 사전 모델 중 ImageBind를 사용했다. 이 인코더는 6개의 방식들 사이에서 통합적으로 좋은 성능을 보인다. ImageBind를 사용해서 여러 개의 인코더를 이용하지 않을 수 있었다. 이 인코더를 통해 다른 표현의 인풋들이 언어 같은 LLM이 이해할 수 있는 표현으로 매핑된다.
- LLM Understanding and Reasoning Stage: 두 번째 계층의 LLM으로는 Vicuna를 이용한다. 이는 MM-LLM 중 하나인 오픈 소스 텍스트 기반 LLM으로 널리 사용되는 것이다. 다른 방식의 표현을 input으로 받고 의미론적 이해와 추론을 이끌어낸다. 이 모델의 output은 1) 직접적인 텍스트 response 2) (필요하다면) multimodal 콘텐츠를 만들기 위한 디코딩 층이 받아 변환하게 하는 설명인 각 방식의 signal 토큰 이렇게 2개이다.
- Multimodal Generation Stage: LLM으로부터 multimodal signal을 받으면, 트랜스포머 기반 output projection layers에서 signal token 표현을 이해할 수 있도록 디코딩한다. 이때, 디퓨전 모델을 이용하는데 이미지를 위해서는 Stable Diffusion을, 비디오를 위해서는 Zeroscope를, 오디오를 위해서는 AudioLDM을 이용한다. 이 전체 모델에서는 일부의 파라미터만 학습하고 인코더/디코더의 나머지 파라미터는 동결시킨다. 결과적으로, 전체 파라미터의 1% 정도만 업데이트한다. 이것이 NExT-GPT의 주요 이점 중 하나라고도 설명한다. 파라미터 요약 표는 아래와 같다.

4. Lightweight Multimodal Alignment Learning
4.1. Encoding-side LLM-centric Multimodal Alignment
대부분의 기존 MM-LLM은 트랜스포머 기반의 multimodal 인코더를 선택하여 패치 수준의 그리드를 생성한다. 이들은 선형 레이어를 통해 핵심 LLM이 이해할 수 있도록 변환한다. 그러나 언어 토큰은 항상 별도의 개념을 캡슐화하기 때문에 패치 기반 단위는 복잡한 텍스트 토큰 의미와 잘 일치하지 않을 수 있다. 따라서 그리드 수준의 특징을 그룹화 메커니즘을 통해 의미론적 개념 토큰으로 계층적으로 집계한 다음 이 개념 수준의 토큰을 LLM에 공급할 수 있도록 설계했다고 한다. 이 알고리즘을 위해 기존 말뭉치 및 벤치마크의 'X-캡션' 쌍 데이터, 즉 'X'(이미지, 오디오, 비디오 등)라는 표현이 주어졌을 때 훈련된 'X-to-test' 생성 작업 데이터를 이용하여 LLM이 해당 텍스트 설명을 생성하도록 한다. 'X-캡션' 쌍 데이터로는 '비디오-캡션' 쌍 데이터셋을 포함한 세 가지 유형의 데이터를 활용한다. (이미지 캡션 쌍, 오디오 캡션 쌍 등.) 아래 이미지가 바로 그 학습 과정이다.
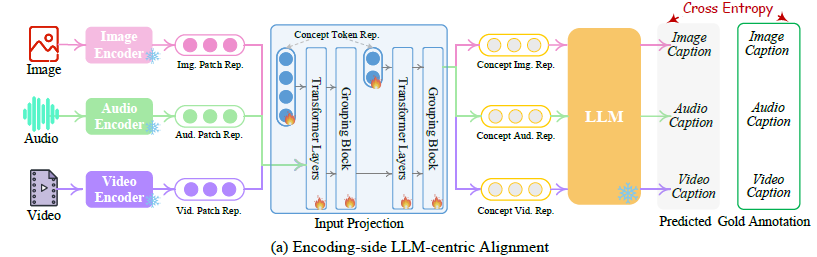
4.2. Decoding-side Instruction-following Alignment
이 부분의 목적은 LLM의 출력 instruction과 디퓨전 모델을 align하는 것이다. 그러나 full-scale alginment는 계산적으로 너무 복잡하기 때문에 docoding-side instruction-following alignment를 이용한다. 이는 textual instruction을 직접 바로 output으로 하는 대신 [IMG_i]와 같은 스페셜 토큰을 이미지 signal token으로, [AUD_i]를 오디오 signal token으로, [VID_i]를 비디오 시그널 토큰으로 디자인하여 디퓨전 모델에게 풍부하고 유연한 instruction을 전달할 수 있게 한 방식이다. 이때 디퓨전 모델이 LLM의 signal token 표현을 알아들을 수 있도록 노이즈 제거 과정의 조건부 입력으로 LLM의 modal signal token 표현을 이용하여 디퓨전 모델이 적절한 이미지, 비디오 또는 오디오를 생성할 수 있도록 하기도 한다. 본 alignment의 훈련 과정에서는, CC3M, WebVid, AudioCaps의 캡션을 인풋으로 하고 합친 다음 signal token을 output으로 하는 데이터를 이용했고, 손실 함수는 1) negative log-likelihood of producing signal tokens, 2) the caption alignment loss, 3) conditional latent denoising loss 이렇게 3가지를 포함하게 설정했다고 한다. 이 과정을 그림으로 나타내면 아래와 같다.
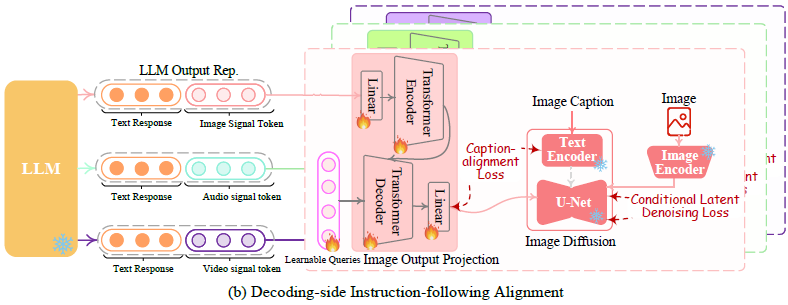
5. Modality-switching Instruction Tuning
5.1. Instruction Tuning
MM-LLM을 (INPUT, OUTPUT) 쌍의 데이터로 학습시킨다. 이때 LoRA 기법을 써서 NExT-GPT의 파라미터들이 동시에 업데이트될 수 있도록 했다. 이 과정을 그림으로 나타내면 아래와 같다.

5.2. Instruction Dataset
데이터셋으로 'Text' → 'Text + X' 데이터셋과 'Text + X' → 'Text' 데이터셋을 수집하여 이용했다. 그 예시로는 MosIT Dataset 등이 있다. (자세한 데이터셋 수집 및 활용 과정은 논문을 참고하자)
6. Experiments
6.1. Main Results
Multimodal Perception: NExT-GPT가 이미지, 오디오, 비디오로부터 그 의미를 얼마나 잘 해석하는지를 평가한 결과로, 아래 표와 같다. 좋은 결과를 보이는 것을 알 수 있다.

Multimodal Generation: 이미지, 비디오, 또는 오디오와 텍스트의 합성 퀄리티를 평가했다. 그 결과가 아래 표로, 역시 좋은 성능을 보인다.

6.2. In-depth Analysis
The Impact of Signal Token Numbers, The Impact of Grouping Mechanism, Evaluation on Pipeline vs End-to-End MM-LLMs 등을 주제로 더 탐구했다. 자세한 내용은 논문을 참고하자.
*실제 사용 예시 이미지

'논문 리뷰' 카테고리의 다른 글
| LARGE LANGUAGE MODELS AS OPTIMIZERS by Google DeepMind (6) | 2024.09.01 |
|---|---|
| Self-Rewarding Language Models by Meta AI (6) | 2024.09.01 |

