1. 이론적 배경
1-1. 딥러닝
딥러닝은 인공지능(AI)과 머신러닝의 중요한 부분으로, 복잡한 데이터에서 패턴을 학습하는 데 사용되는 심층 신경망 기술을 말한다. 딥러닝은 데이터의 추상적인 특징을 자동으로 학습할 수 있도록 한다.
1-2. 딥러닝 모델
1-2-1. 다층 퍼셉트론(MLP)
구조 및 기능: 다층 퍼셉트론은 가장 기본적인 신경망 구조로, 입력층, 하나 또는 여러 개의 은닉층, 그리고 출력층으로 구성된다. 각 층은 여러 개의 노드(뉴런)로 이루어져 있으며, 노드들은 가중치를 통해 서로 연결된다. 데이터가 입력층을 통해 네트워크에 들어가면, 각 은닉층을 거치며 가중치와 활성화 함수를 통해 처리된 후 최종적으로 출력층에서 결과가 생성된다. MLP는 주로 분류, 회귀 분석 등에 사용된다.

특징: 가장 기본적인 인공신경망 구조를 가지며, 다양한 데이터를 처리할 수 있지만, 깊은 네트워크에서는 학습이 어렵고, 이미지나 시계열 데이터 처리에는 비효율적이다.
1-2-2. 합성곱 신경망(CNN)
구조 및 기능: CNN은 이미지 처리에 주로 사용되는 신경망으로, 합성곱 계층(convolutional layers), 활성화 함수, 풀링 계층(pooling layers), 그리고 완전 연결 계층(fully connected layers)으로 구성된다. 합성곱 계층에서는 입력 이미지에서 특징을 추출하며, 풀링 계층에서는 특징의 크기를 줄여 계산량을 감소시킨다. 마지막으로 완전 연결 계층에서는 특징들을 바탕으로 분류나 회귀 등의 작업을 수행한다.
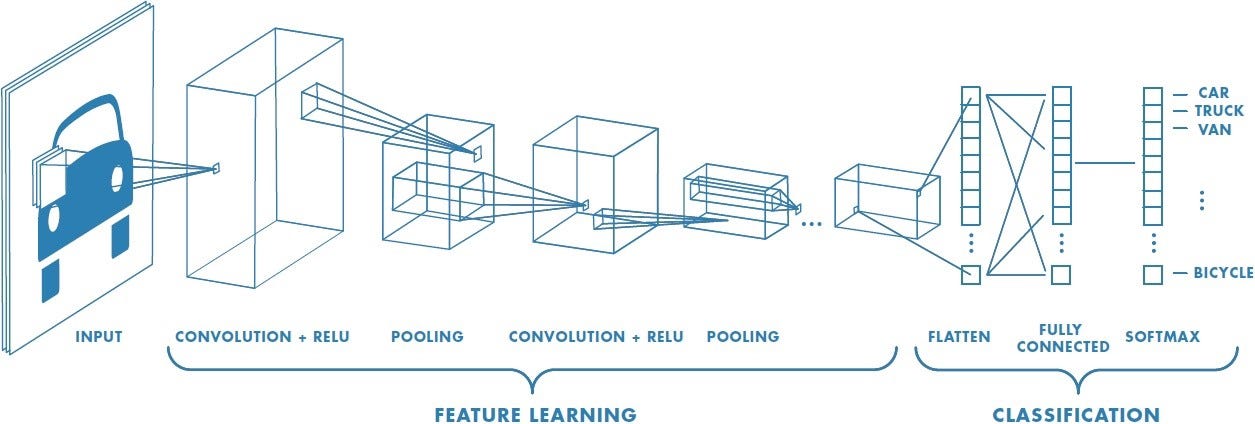
특징: 이미지의 공간적 계층 구조를 학습할 수 있어 이미지 인식과 분류에서 뛰어난 성능을 보이지만, 구조가 복잡하고 많은 계산량을 요구한다.
1-2-3. 순환 신경망(RNN)
구조 및 기능: RNN(Recurrent Neural Network)은 시퀀스 데이터 처리에 적합한 신경망 구조이다. RNN의 핵심적인 특징은 네트워크 내의 순환(loop)이 있어서, 이전의 정보를 기억하면서 새로운 입력에 대해 반응할 수 있다는 점이다. 기본적인 RNN 셀은 크게 두 부분으로 나눌 수 있는데, 이는 현재 시점의 입력을 받는 부분과 이전 시점의 출력(상태)을 받는 부분이다.
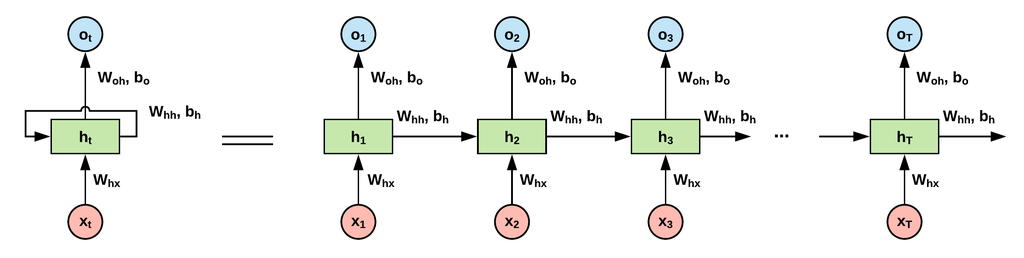
- 현재 입력(X_t): 시간 t에서의 입력이다.
- 이전 상태(h_{t-1}): 시간 t-1에서의 출력(혹은 상태)이다. 이전의 정보를 담고 있으며, RNN의 핵심적인 요소이다.
- 현재 상태(h_t): 현재 입력과 이전 상태를 기반으로 계산된다. 이것은 현재 시점의 출력으로도 사용되며, 다음 시점으로 전달되어 이전 상태 정보를 제공한다.
- 가중치(W): 입력과 이전 상태에 적용되는 가중치이다. 학습 과정에서 최적화된다.
작동 과정
- 초기 상태 설정: 최초의 이전 상태(h_0)는 보통 0 또는 무작위 작은 값으로 초기화된다.
- 시간 t에서의 계산:
- 현재 시점 t의 입력(X_t)과 이전 시점 t-1의 상태(h_{t-1})를 받는다.
- 이 두 정보를 가중치 W와 결합하고, 활성화 함수(예: tanh, ReLU)를 통해 현재 시점 t의 상태(h_t)를 계산한다.
- 이 상태(h_t)는 필요에 따라 출력으로 사용되며, 다음 시점 t+1의 계산을 위해 이전 상태로 전달된다.
- 순환 반복: 모든 시퀀스 데이터가 네트워크를 통과할 때까지 이 과정을 반복한다.
특징
- 메모리 기능: RNN은 이전의 정보를 현재의 결정에 반영할 수 있는 내부 메모리를 가지고 있다. 이를 통해 시퀀스의 컨텍스트를 이해하고, 시간적인 패턴을 학습할 수 있다.
- 가변 길이 입력 처리: RNN은 가변 길이의 시퀀스 데이터를 처리할 수 있다. 이는 자연어 처리(NLP), 시계열 분석 등 다양한 분야에서 RNN이 유용하게 사용될 수 있는 이유 중 하나다.
- 장기 의존성 문제: 기본 RNN은 장기간에 걸친 의존성을 학습하는 데 어려움이 있다. 이를 해결하기 위해 LSTM(Long Short-Term Memory) 같은 고급 RNN 구조가 개발되었다.
1-2-4. LSTM(Long Short-Term Memory)
구조 및 기능: LSTM은 순환 신경망(RNN)의 한 종류로, RNN의 장기 의존성 문제를 해결하기 위해 설계되었다. LSTM의 핵심은 '셀 상태'라는 내부 메커니즘을 통해 정보를 장기간 저장하고, 필요에 따라 정보를 추가하거나 삭제하는 능력이다. LSTM 셀은 크게 세 가지 주요 게이트로 구성되는데, 입력 게이트, 삭제 게이트, 출력 게이트이 그것이다. 이 게이트들은 셀 상태와 출력을 조절하는 데 핵심적인 역할을 한다.
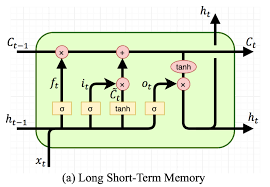
- 입력 게이트: 새로운 정보를 셀 상태에 추가할지 결정한다.
- 삭제 게이트: 셀 상태에서 어떤 정보를 삭제할지 결정한다.
- 출력 게이트: 셀 상태를 기반으로 어떤 값을 출력할지 결정한다.
작동 과정
- 삭제 게이트: 시간 t에서 첫 번째 단계는 어떤 정보를 셀 상태에서 삭제할지 결정하는 것이다. 이전 상태 (h_{t-1})과 현재 입력 (x_t)를 받아 시그모이드 함수를 적용한다. 이 함수의 출력은 0과 1 사이의 값으로, 셀 상태의 각 부분이 얼마나 중요한지를 결정한다(0은 "전혀 중요하지 않음", 1은 "매우 중요").
- 입력 게이트: 다음으로, 어떤 새로운 정보를 셀 상태에 저장할지 결정한다. 이 과정은 두 부분으로 나뉜다. 첫 번째는 시그모이드 함수를 사용해 어떤 값을 업데이트할지 결정하고, 두 번째는 tanh 함수를 사용해 새로운 후보 값 (C_t)를 생성하여 셀 상태에 추가할 수 있는 값을 생성한다.
- 셀 상태 업데이트: 이전 단계에서 삭제할 정보를 제거하고, 새로운 정보를 추가함으로써 셀 상태 (C_{t-1})를 업데이트한다. 이는 이전 셀 상태에서 삭제 게이트의 출력에 따라 일부 정보를 제거하고, 입력 게이트에서 생성된 새로운 후보 값을 추가함으로써 이루어진다.
- 출력 게이트와 셀 출력: 마지막 단계는 셀의 출력, 즉 다음 상태 (h_t)를 결정하는 것이다. 시그모이드 함수를 사용해 셀 상태의 어떤 부분을 출력할지 결정하고, 셀 상태를 tanh 함수에 통과시켜 -1과 1 사이의 값을 얻은 다음, 이를 시그모이드 게이트의 출력과 곱하여 실제 출력 (h_t)를 결정한다.
특징
- LSTM은 장기 의존성 문제를 해결하기 위해 설계되었으며, 복잡한 시퀀스 데이터에서 중요한 패턴을 학습할 수 있다.
- 다양한 시퀀스 데이터 처리 작업(기계 번역, 음성 인식, 텍스트 생성 등)에 사용된다.
1-3. 축구 데이터
1-3-1. FIFA rating
EA Sports에서는 Mueller-Moehring의 EA 프로듀서 팀이 감독하여 선수들의 데이터를 관리하고 있다. 그 팀은 25명의 EA 프로듀서와 400명의 외부 데이터 기여자로 구성되어있다. 그러나 EA Sports의 직원이 매 경기마다 모든 선수를 지켜보는 것은 불가능하기 때문에, 6,000명 이상의 자원봉사자로 구성된 팀이 1년 내내 선수 데이터베이스를 유지하고 업데이트하는 데 도움을 준다고 한다. 게임 능력치에는 신체적 능력치(가속력, 속력, 민첩성, 밸런스, 점프, 스태미너, 몸싸움), 정신적 능력치(적극성, 침착성, 가로채기, 위치선정, 반응속도, 시야), 개인기 능력치(볼 컨트롤, 드리블, 크로스, 긴 패스, 짧은 패스, 커브, 슛 파워, 중거리 슛, 골 결정력, 프리킥, 페널티 킥, 헤더, 발리 슛, 대인수비, 슬라이딩 태클, 태클), 골키퍼 능력치(GK 다이빙, GK 핸들링, GK 킥, GK 반응속도)가 있다.
선수의 최종 전체 등급이 계산되는 방식은 위의 능력치들과 선수의 국제적 인지도, 포지션에 따라 다르게 결정된다. 기존 세부 능력치에 골키퍼, 수비수, 미드필더, 공격수에 따라 다른 포지션 계수와 능력치를 곱하고 국제적 평판의 영향까지 반영하여 최종 등급이 계산된다. 또한, 본 등급은 매년 1~2월에 업데이트된다. 본 탐구에서는 이 선수의 최종 등급을 데이터로 이용할 것이다.
1-3-2. xG, xAG
- 기대득점(xG): 기대득점(xG)은 슈팅의 질을 나타내며, 특정 슈팅이 골로 이어질 확률을 나타내는 통계적 척도이다. 이 값은 0.00에서 1.00 사이로 표현되며, 골 기회의 질을 수치화한다. xG 값은 슈팅의 위치, 슈팅까지의 과정, 수비수의 위치, 골키퍼의 위치 등 여러 요소를 고려하여 계산된다. 예를 들어, 페널티 박스 안에서의 슈팅은 멀리 떨어진 곳에서의 슈팅보다 높은 xG 값을 가진다. xG 모델은 30만 건 이상의 슈팅 데이터를 기반으로 한다. 이 데이터는 슈팅의 위치, 각도, 슈팅까지의 과정(예: 패스, 돌파), 수비수의 위치, 골키퍼의 위치 등 다양한 변수를 포함한다.
- 기대실점(xAG): 기대 실점(xAG)은 상대방의 슈팅이 골로 이어질 확률을 반영한 수치로, 팀의 수비력과 골키퍼의 성능을 평가하는 데 사용된다. 이 수치는 팀이 얼마나 많은 실점 기회를 상대에게 허용했는지를 나타낸다. xAG는 팀의 수비 전략과 골키퍼의 성능을 분석하는 데 중요한 지표이다. 낮은 xAG 값은 팀이 상대의 공격을 효과적으로 막아내고 있다는 것을 의미다. xAG는 상대방의 슈팅 기회의 질을 반영하여, 팀의 수비력과 골키퍼의 성능을 평가하는 데 사용된다. 이는 팀이 얼마나 효과적으로 상대의 공격을 막아냈는지를 수치화한다. 이를 통해 골키퍼의 성능을 객관적으로 평가할 수 있다.
1-4. 선행 논문 탐색
1). European Soccer League Outcome Predictor, Sang Ahn(Stanford University) 외, 2022.
- dataset:
이 논문에서는 Kaggle에서 가져온 2008/2009~2015/2016 시즌에 걸쳐 유럽 상위 5개 축구 리그의 경기 데이터를 활용한다. 이 데이터셋는 약 12,633개의 경기로 구성되어 있으며 영국, 프랑스, 독일, 이탈리아 및 스페인의 리그에 중점을 두고 있다. 추출된 기능에는 경기 형식, 공격 및 수비 성능(득점/실점 수), Bet365의 경기 전 베팅 확률 등 팀 수준 데이터가 포함된다.
- 사용된 알고리즘 및 모델:
사용된 핵심 알고리즘은 기존 팀 지표와 함께 플레이어 수준 데이터로 보강된 완전 연결 신경망이다. 모델 아키텍처는 Leaky ReLU 활성화 함수, 소프트맥스 출력 레이어, 향상된 일반화를 위한 드롭아웃 정규화를 갖춘 5개의 숨겨진 레이어로 구성했다. 활용되는 손실 함수는 범주형 교차 엔트로피이다. 또한 효율적인 경사 하강을 위해 Adam 최적화를 사용했다.
- 결과:
개발된 모델은 팀 ELO 점수에만 의존하는 기본 모델에 비해 향상된 예측 정확도를 보여주었다. 테스트셋에서 기본 모델은 50.46%의 정확도를 달성하여 기본 정확도 45.62%를 능가했다. 그러나 모델은 본질적으로 더 예측하기 어려운 무승부 결과를 예측하는 데 특히 어려움을 겪는다고 한다.
2). Football Match Prediction using Deep Learning, Ahmed Amr Awadallah (Stanford University) 외, 2020.
- dataset:
연구진은 2008/2009시즌부터 2018/2019시즌까지 프리미어리그 경기 데이터(총 4180행 x 78열)를 분석했다.
추출된 feature에는 경기 세부 정보(날짜, HomeTeam, AwayTeam, FTHG, FTAG, FTR, HTAG 등), 베팅 확률, FIFA 통계 및 Elo 순위가 포함된다. 예측에 사용된 최종 기능에는 홈 및 원정 팀 Elo 점수, 마지막 경기 이후 일수, 승률 및 무승부 비율, 최근 성적 동향, 현재 시즌 통계가 포함되었다.
- 사용된 알고리즘 및 모델:
추출된 24개의 특징을 기반으로 일치 결과를 예측하기 위해 가중 행렬 초기화를 사용하여 기준 모델로 구현하는 로지스틱 회귀를 사용했다. 또한, Random Forest Classifier를 사용하여 데이터의 비선형 패턴을 포착하여 각 경기 결과에 대한 예측 확률을 제공하는 데 활용했다. 은닉계층에 300개 및 100개의 노드가 있는 3계층 완전히 연결된 네트워크를 사용하고 소프트맥스 활성화 및 교차 엔트로피 손실을 사용하여 30,000 에포크 동안 훈련한 신경망도 이용했다. LSTM(Long Short-Term Memory) 또한 LSTM 레이어와 소프트맥스 출력으로 매치 데이터의 순차적 정보를 캡처하는 데 활용했다.
- 결과:
로지스틱 회귀는 약 60.95%의 train data 정확도와 53.68%의 test data 정확도를 달성했다. Random Forest Classifier는 train data 정확도는 78.5%로 나타났지만 test data 정확도는 40.66%로 낮아 과적합 문제가 있었다. 신경망 중 가장 성능이 좋은 아키텍처는 30,000 에포크 훈련 이후 train data 정확도가 61.46%, test data 정확도가 56.36%였다. LSTM 같은 경우 train data 정확도는 59.5%, test data 정확도는 58.2%로 다른 모델보다 뛰어난 성능을 보였지만 무승부 예측에는 여전히 성능이 좋지 못했다.
2. 모델링
2-1. 데이터 사용
2-1-1. 승부 예측 인공지능
보유한 데이터: 년도별 프리미어리그 경기 결과 데이터(1993-2024), 년도별 선수들의 피파 능력치(전체 능력치 및 세부 능력치, 2005-2024)
이용할 데이터: 각각의 팀의 FIFA rating 평균 및 최고 rating, 각각의 팀의 홈/어웨이 승률
데이터 사용 이유: 각각의 팀의 FIFA rating의 평균 및 최고 점수가 각각의 팀의 수준을 나타내고, 또한 홈/어웨이 승률으로 각 팀의 상대팀에 대한 우위 정도를 파악할 수 있기 때문에 각각의 팀의 승률을 데이터로 이용한다.
데이터 전처리: 년도별 각각의 팀의 FIFA rating(전체 능력치) 평균 및 최고 rating(전체 능력치)을 정리한 데이터 셋을 만든다. 또한, 년도별 프리미어리그 경기 결과 데이터를 통해 각각의 팀의 년도별 홈/어웨이 승률을 정리한 데이터 셋을 만들어 학습에 활용한다.
2-1-2. 스코어 예측 인공지능
보유한 데이터: 년도별 프리미어리그 팀들의 xG 값(2016-2024), 년도별 프리미어리그 경기 결과 데이터(1993-2024), 년도별 선수들의 피파 능력치(전체 능력치 및 세부 능력치, 2005-2024)
이용할 데이터: 각각의 팀의 FIFA rating 평균 및 최고 rating, 각각의 팀의 FIFA 골 결정력/골키퍼 반응속도 능력치 rating 평균 및 최고 rating, 각각의 팀의 홈/어웨이 평균 득점, 각각의 팀의 홈/어웨이 평균 실점, 각각의 팀의 xG 값
데이터 사용 이유: 각각의 팀의 FIFA rating의 평균 및 최고 점수가 각각의 팀의 수준을 나타내고, 또한 홈/어웨이 승률으로 각 팀의 상대팀에 대한 우위 정도를 파악할 수 있기 때문에 각각의 팀의 승률을 데이터로 이용한다. 여기다가 각각의 팀의 골 결정력/골키퍼 반응속도 능력치가 득점/실점에 가장 큰 영향을 미친다고 판단하여 이 능력치도 학습 데이터에 추가할 것이다. 또한 정확한 과거의 스코어라인 결과를 학습 데이터에 추가하여 각 팀의 상대팀에 대한 득점/실점 정도를 파악할 것이다.
데이터 전처리: 년도별 각각의 팀의 FIFA rating(전체 능력치) 평균 및 최고 rating(전체 능력치)을 정리한 데이터 셋을 만든다. 이때, 특히 세부 능력치 중 골 결정력 및 골키퍼 반응속도 능력치는 데이터셋을 따로 또 구성하여 모델에 학습시킬 수 있도록 한다. 또한, 년도별 프리미어리그 경기 결과 데이터를 통해 각각의 팀의 년도별 홈/어웨이 평균 득점 및 평균 실점을 정리한 데이터셋을 만든다. 마지막으로, 년도별 프리미어리그 팀들의 xG 값 데이터셋을 정리하여 학습에 활용한다.
2-2. 딥러닝 모델 사용
우선적으로 사용할 모델: RNN, LSTM
이유: 축구 팀의 선수진은 시간이 지날수록 변화하고 축구 전술 양상 및 규칙도 시간에 따라 변화하기 때문에 비교적 과거의 데이터는 현재에 영향을 미치는 정도가 적을 수밖에 없다. 따라서 현재의 데이터가 미래의 예측에 보다 많은 영향을 미치게 하기 위해서 시계열 데이터를 다루는 분야에 장점이 있는 RNN과 LSTM 모델을 사용할 것이다.
사용해본 뒤 성능을 비교해볼 모델: 다층 퍼셉트론, CNN
(위의 모델들도 예상치 못한 좋은 결과를 보일 수 있기 때문에 사용해본 뒤 성능을 비교해볼 계획이다.)
'정보과학융합탐구' 카테고리의 다른 글
| [정융탐] EPL 축구 경기 승부예측 AI 개발 프로젝트 (4) (1) | 2024.07.08 |
|---|---|
| [정융탐] EPL 축구 경기 승부예측 AI 개발 프로젝트 (3) (0) | 2024.06.23 |
| [정융탐] EPL 축구 경기 승부예측 AI 개발 프로젝트 (2) (0) | 2024.05.27 |
| [정융탐] EPL 축구 경기 승부예측 AI 개발 프로젝트 계획 (2) | 2024.03.23 |


