1. 데이터 수집 및 전처리
현재 보유한 데이터와 본 탐구에서 AI 모델별로 개발 과정에서 이용할 데이터는 각각 다음과 같다.
- 승부 예측 인공지능
보유한 데이터: 년도별 프리미어리그 경기 결과 데이터(1993-2024), 년도별 선수들의 피파 능력치(전체 능력치 및 세부 능력치, 2005-2024)
이용할 데이터: 각각의 팀의 FIFA rating 평균 및 최고 rating, 각각의 팀의 홈/어웨이 승률
- 스코어 예측 인공지능
보유한 데이터: 년도별 프리미어리그 팀들의 xG 값(2016-2024), 년도별 프리미어리그 경기 결과 데이터(1993-2024), 년도별 선수들의 피파 능력치(전체 능력치 및 세부 능력치, 2005-2024)
이용할 데이터: 각각의 팀의 FIFA rating 평균 및 최고 rating, 각각의 팀의 FIFA 골 결정력/골키퍼 반응속도 능력치 rating 평균 및 최고 rating, 각각의 팀의 홈/어웨이 평균 득점, 각각의 팀의 홈/어웨이 평균 실점, 각각의 팀의 xG 값
이 중 스코어 예측 인공지능은 후속 연구로 계획 중이므로, 승부 예측 인공지능에 필요한 데이터셋부터 준비할 것이다.
1-1. 각각의 팀의 홈/어웨이 승률
먼저 1993~2023년까지의 프리미어리그 경기 결과 데이터셋을 불러와서 그 형태를 확인해보았다.
import pandas as pd
data = pd.read_csv('/content/drive/MyDrive/footballAI/premier-league-matches.csv')
print(data)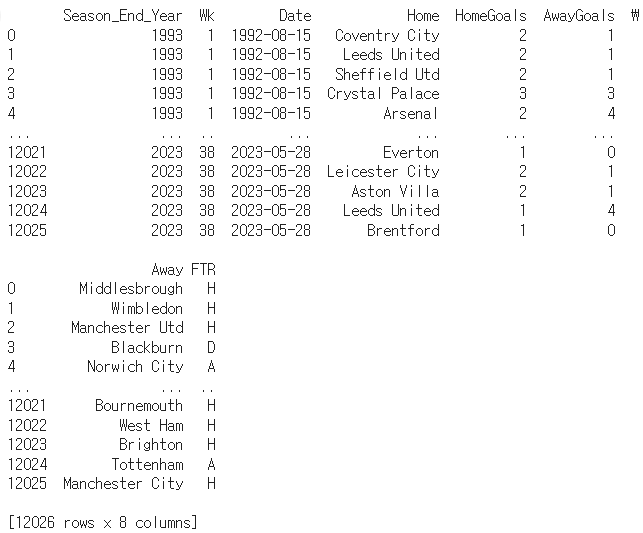
출력 결과 각 행마다 한 경기씩 나와 있고, 각 경기별로 그 경기가 일어난 년도(Season_End_Year)와 홈 팀(Home), 원정 팀(Away), 경기 스코어, 경기 결과(FTR - H:홈팀 승리, A:어웨이 팀 승리, D: 무승부)가 나와 있다. 각각의 팀 별로 년도별 승률을 계산하기 위해 먼저 총 팀의 수와 년도를 알아보았다.
teams = list(sorted(set(data['Home'])))
print(teams)
total_team_num = len(teams)
print(total_team_num)
total_years = len(set(data['Season_End_Year']))
print(total_years)출력 결과는 아래와 같았다. 총 팀 수는 50팀이었으며, 총 년도는 1993~2023년까지 31년이었다.
['Arsenal', 'Aston Villa', 'Barnsley', 'Birmingham City', 'Blackburn', 'Blackpool', 'Bolton', 'Bournemouth', 'Bradford City', 'Brentford', 'Brighton', 'Burnley', 'Cardiff City', 'Charlton Ath', 'Chelsea', 'Coventry City', 'Crystal Palace', 'Derby County', 'Everton', 'Fulham', 'Huddersfield', 'Hull City', 'Ipswich Town', 'Leeds United', 'Leicester City', 'Liverpool', 'Manchester City', 'Manchester Utd', 'Middlesbrough', 'Newcastle Utd', 'Norwich City', "Nott'ham Forest", 'Oldham Athletic', 'Portsmouth', 'QPR', 'Reading', 'Sheffield Utd', 'Sheffield Weds', 'Southampton', 'Stoke City', 'Sunderland', 'Swansea City', 'Swindon Town', 'Tottenham', 'Watford', 'West Brom', 'West Ham', 'Wigan Athletic', 'Wimbledon', 'Wolves']
50
31
다음으로 각각의 팀의 홈/어웨이 승률을 계산하기 전에 전체 승률부터 한 번 계산해 보았다. 각각의 팀의 총 경기 수와 승리한 경기 수를 2차원 배열(년도 * 팀 수)에 저장한 다음, 이를 바탕으로 승률(승리한 경기 수/총 경기 수)을 계산하였다.
wins = [[0]*total_team_num for _ in range(total_years)]
games = [[0]*total_team_num for _ in range(total_years)]
for i in range(total_years):
for j in range(len(data)):
if data['Season_End_Year'][j] == i+1993:
if data['FTR'][j] == 'H':
win_id = teams.index(data['Home'][j])
lose_id = teams.index(data['Away'][j])
wins[i][win_id] += 1
elif data['FTR'][j] == 'A':
win_id = teams.index(data['Away'][j])
lose_id = teams.index(data['Home'][j])
wins[i][win_id] += 1
else:
win_id = teams.index(data['Away'][j]) #무승부이므로 승리 여부 상관 X
lose_id = teams.index(data['Home'][j]) #무승부이므로 승리 여부 상관 X
games[i][win_id] += 1
games[i][lose_id] += 1
print(wins)
print(games)win_rates = [[0]*total_team_num for _ in range(total_years)]
for i in range(total_years):
for j in range(total_team_num):
if games[i][j] != 0:
win_rates[i][j] = wins[i][j]/games[i][j]
else:
win_rates[i][j] = 'None'
print(win_rates)이때 주의할 점은 각각의 년도 중 프리미어리그의 승강제로 인하여 팀이 매 시즌마다 바뀌었다는 점이다. 따라서 그 전 시즌에 강등된 팀은 경기 수가 아예 없다. 그래서 이 경우를 따로 구분하여 승률을 'None'으로 표시해 주었다.
예를 들어 가장 최근(2023년)의 토트넘의 승률을 출력해보면 0.47정도인 것을 알 수 있다.
print(win_rates[-1][teams.index('Tottenham')])출력 결과: 0.47368421052631576
이후 각각의 팀의 홈/어웨이 승률을 계산하기 위해 경기 결과가 'H'면 홈 팀이 승리한 경기 수에 1을 더하고, 'A'면 어웨이 팀이 승리한 경기 수에 1을 더하며, 둘 다 아니면('D') 무승부이므로 총 경기 수에만 각각의 팀에 1을 더했다. 이때 저번 달 탐구에서 선행 연구 시 무승부를 잘 맞추지 못한다는 결과가 떠올라 각각의 팀의 무승부 확률도 따로 계산해 주기로 했다. 따라서 각각의 팀의 총 홈 경기 수, 총 어웨이 경기 수, 총 홈 승리 수, 총 어웨이 승리 수, 총 무승부 수를 계산한 뒤 (총 홈 승리 수)/(총 홈 경기 수)로 홈 승률을 구하고 (총 어웨이 승리 수)/(총 어웨이 경기 수)로 어웨이 승률을 구했으며 (총 무승부 수)/(총 경기 수)로 무승부 확률을 구했다. (이때 총 경기 수는 앞서 총 승률을 구할 때 계산한 games를 이용했다.)
home_wins = [[0]*total_team_num for _ in range(total_years)]
home_games = [[0]*total_team_num for _ in range(total_years)]
away_wins = [[0]*total_team_num for _ in range(total_years)]
away_games = [[0]*total_team_num for _ in range(total_years)]
draws = [[0]*total_team_num for _ in range(total_years)]
for j in range(len(data)):
i = data['Season_End_Year'][j]-1993
if data['FTR'][j] == 'H':
win_id = teams.index(data['Home'][j])
lose_id = teams.index(data['Away'][j])
home_wins[i][win_id] += 1
home_games[i][win_id] += 1
away_games[i][lose_id] += 1
elif data['FTR'][j] == 'A':
win_id = teams.index(data['Away'][j])
lose_id = teams.index(data['Home'][j])
away_wins[i][win_id] += 1
away_games[i][win_id] += 1
home_games[i][lose_id] += 1
else:
draw_id1 = teams.index(data['Away'][j])
draw_id2 = teams.index(data['Home'][j])
away_games[i][draw_id1] += 1
home_games[i][draw_id2] += 1
draws[i][draw_id1] += 1
draws[i][draw_id2] += 1
print(home_wins)
print(away_wins)
print(home_games)
print(away_games)
print(draws)home_win_rates = [[0]*total_team_num for _ in range(total_years)]
away_win_rates = [[0]*total_team_num for _ in range(total_years)]
draw_rates = [[0]*total_team_num for _ in range(total_years)]
for i in range(total_years):
for j in range(total_team_num):
if games[i][j] != 0:
home_win_rates[i][j] = home_wins[i][j]/home_games[i][j]
away_win_rates[i][j] = away_wins[i][j]/away_games[i][j]
draw_rates[i][j] = draws[i][j]/games[i][j]
else:
home_win_rates[i][j] = 'None'
away_win_rates[i][j] = 'None'
draw_rates[i][j] = 'None'
print(home_win_rates)
print(away_win_rates)
print(draw_rates)이번 경우도 마찬가지로 경기 수가 없는 경우 모든 승률 및 무승부 확률을 'None'으로 표시했다. 그러나 이렇게 'None'으로 처리된 데이터를 학습에 사용할 경우 제대로 된 학습이 이뤄지지 않을 것이다. 따라서 일단 임시방편으로 'None'으로 처리된 데이터를 모두 그 팀의 'None'이 아닌 데이터의 평균으로 바꾸어 주었다. (후처리 과정에서 실제로 일어난 경기에만 본 데이터가 사용되어 훈련 및 테스트 데이터에 들어가기 때문에 사실 이 과정은 큰 의미가 없다.)
for i in range(total_years):
for j in range(total_team_num):
if home_win_rates[i][j] == 'None':
home_win_rates[i][j] = sum([f[j] for f in home_win_rates if f[j]!='None'])/len([f[j] for f in home_win_rates if f[j]!='None'])
away_win_rates[i][j] = sum([f[j] for f in away_win_rates if f[j]!='None'])/len([f[j] for f in away_win_rates if f[j]!='None'])
draw_rates[i][j] = sum([f[j] for f in draw_rates if f[j]!='None'])/len([f[j] for f in draw_rates if f[j]!='None'])이후 이 데이터를 CSV 파일로 정리하기 위해 간단한 정리 과정을 거친 뒤 CSV 파일로 저장해 주었다.
for i in range(total_team_num):
teams[i] = [teams[i]+'_homewin',teams[i]+'_awaywin', teams[i]+'_draw']
Team = ['years']
for i in range(total_team_num):
Team.append(teams[i][0])
Team.append(teams[i][1])
Team.append(teams[i][2])
print(Team)
Final_dataset = [Team]
for i in range(total_years):
l = [i+1993]
for j in range(total_team_num):
l.append(home_win_rates[i][j])
l.append(away_win_rates[i][j])
l.append(draw_rates[i][j])
Final_dataset.append(l)
print(Final_dataset)with open("/content/drive/MyDrive/footballAI/Final_dataset.csv", "w") as file:
writer = csv.writer(file)
writer.writerows(Final_dataset)이렇게 저장된 CSV 파일의 일부는 다음과 같다. 각각의 년도별 팀의 홈 승률, 어웨이 승률, 무승부 확률이 잘 저장된 것을 볼 수 있다.

1-2. 각각의 팀의 FIFA rating 평균 및 최고 rating
각각의 년도의 FIFA 데이터셋의 경우 2005~2024년까지 그 데이터가 있었는데, 각각의 데이터가 2005~2020, 2021, 2022, 2023, 2024 이렇게 5개의 CSV파일로 구분되어 있었다. 먼저 2005~2020년의 데이터부터 출력해보았다.
data1_05to20 = pd.read_csv('/content/drive/MyDrive/footballAI/player_stats.csv')
print(data1_05to20)
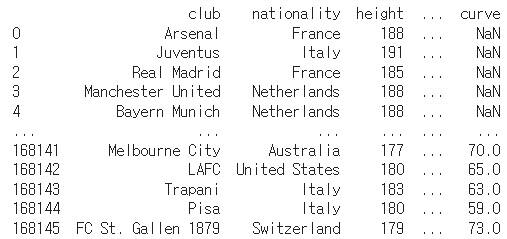
데이터를 살펴보면 선수의 이름, 년도(year), 팀(club) 등이 나와있는 것을 알 수 있다. 가장 중요한 각각의 선수별 총합 FIFA 평점은 'rating' 컬럼에 저장되어 있었다. 이후 이 선수들 중 프리미어리그에 속한 팀의 선수의 평점을 찾아서 각각의 팀의 총 rating의 합에 더하고, 각각의 팀의 총 선수 수를 계산하여 각각의 팀의 평균 rating을 계산하려고 하였다. 그러나 이때 앞서 승률을 계산할 때 나왔던 팀명과 FIFA 데이터셋의 팀명이 맞지 않는 문제가 발생하였다. 그 이유는 각각의 팀명을 어떤 데이터에서는 풀 네임으로 쓰고, 어떤 데이터에서는 줄여서 쓰고 했기 때문에 그 명칭을 통일시켜야 특정 선수가 속한 팀이 프리미어리그에 속했는지의 여부를 판정할 수 있었기 때문이다. 따라서 일일이 각각의 데이터에서 특정 팀의 명칭을 찾아서 수정하는 작업을 반복하였다.
이렇게 탐색 결과 일치하지 않는 팀명을 수정하는 코드는 다음과 같다.
def replace_item(value_l, from_item, to_item):
return [to_item if v == from_item else v for v in value_l]
data1_05to20['club'] = replace_item(data1_05to20['club'],'Bolton Wanderers','Bolton')
data1_05to20['club'] = replace_item(data1_05to20['club'],'Brighton Hove Albion','Brighton')
data1_05to20['club'] = replace_item(data1_05to20['club'],'Blackburn Rovers','Blackburn')
data1_05to20['club'] = replace_item(data1_05to20['club'],'Charlton Athletic','Charlton Ath')
data1_05to20['club'] = replace_item(data1_05to20['club'],'Huddersfield Town','Huddersfield')
data1_05to20['club'] = replace_item(data1_05to20['club'],'Manchester United','Manchester Utd')
data1_05to20['club'] = replace_item(data1_05to20['club'],'Newcastle United','Newcastle Utd')
data1_05to20['club'] = replace_item(data1_05to20['club'],'Nottingham Forest',"Nott'ham Forest")
data1_05to20['club'] = replace_item(data1_05to20['club'],'Queens Park Rangers','QPR')
data1_05to20['club'] = replace_item(data1_05to20['club'],'Reading FC','Reading')
data1_05to20['club'] = replace_item(data1_05to20['club'],'Sheffield United','Sheffield Utd')
data1_05to20['club'] = replace_item(data1_05to20['club'],'Sheffield Wednesday','Sheffield Weds')
data1_05to20['club'] = replace_item(data1_05to20['club'],'Tottenham Hotspur','Tottenham')
data1_05to20['club'] = replace_item(data1_05to20['club'],'West Bromwich','West Brom')
data1_05to20['club'] = replace_item(data1_05to20['club'],'West Ham United','West Ham')
data1_05to20['club'] = replace_item(data1_05to20['club'],'AFC Wimbledon','Wimbledon')
data1_05to20['club'] = replace_item(data1_05to20['club'],'Wolverhampton Wanderers','Wolves')
data1_05to20['club'] = replace_item(data1_05to20['club'],'Chelsea FC','Chelsea')
data1_05to20['club'] = replace_item(data1_05to20['club'],'Arsenal FC','Arsenal')
data1_05to20['club'] = replace_item(data1_05to20['club'],'Nottm Forest',"Nott'ham Forest")
data1_05to20['club'] = replace_item(data1_05to20['club'],'Wolverhampton','Wolves')
data1_05to20['club'] = replace_item(data1_05to20['club'],'Brighton & Hove Albion','Brighton')
data1_05to20['club'] = replace_item(data1_05to20['club'],'West Bromwich Albion','West Brom')
data1_05to20['club'] = replace_item(data1_05to20['club'],'AFC Bournemouth','Bournemouth')
print(data1_05to20['club'])이렇게 팀명을 수정한 데이터셋을 기반으로 각각의 팀 별 총 rating 합과 총 선수 수를 계산하는 코드는 다음과 같다.
Sum_ratings = [[0]*total_team_num for _ in range(total_years)]
players_by_team = [[0]*total_team_num for _ in range(total_years)]
for j in range(len(data1_05to20)):
i = data1_05to20['year'][j]-2005
if data1_05to20['club'][j] in teams:
id = teams.index(data1_05to20['club'][j])
Sum_ratings[i][id] += data1_05to20['rating'][j]
players_by_team[i][id] += 1
print(Sum_ratings)
print(players_by_team)이렇게 총 평점의 합인 Sum_ratings와 총 선수의 수인 players_by_team을 계산해봤을 때, 혹시 특정 년도에 그 팀이 FIFA에 없어서 선수가 한 명도 없게 계산되어버리면 평균 평점을 계산할 수 없게 되므로 그 경우가 있는지를 확인해보았다.
for i in range(total_years):
for j in range(total_team_num):
if Sum_ratings[i][j]==0 or players_by_team[i][j]==0:
print(i,j,teams[j])
각각의 년도와 팀 번호, 팀명을 출력해본 결과 Wimbledon의 경우 많은 년도에 FIFA에 그 데이터가 없는 것을 볼 수 있었는데, 이는 Wimbledon이 그 시즌에 4부리그 이하여서 그런 것으로 보인다. 또한 Oldham Athletic이라는 팀도 데이터가 없는 년도가 있었다. 이렇게 데이터가 없는 경우 평균 평점 및 최고 평점을 승률에서 했던 것처럼 'None'으로 설정하였다. 데이터가 있는 경우 평균 평점은 (총 평점의 합)/(총 선수의 수)로 구했고, 최고 평점은 그 팀에 속한 선수들의 평점 중 최댓값으로 구했다.
Avg_ratings = [[0]*total_team_num for _ in range(total_years)]
MAX_ratings = [[0]*total_team_num for _ in range(total_years)]
for i in range(total_years):
for j in range(total_team_num):
if Sum_ratings[i][j] == 0:
Avg_ratings[i][j] = 'None'
MAX_ratings[i][j] = 'None'
else:
Avg_ratings[i][j] = Sum_ratings[i][j]/players_by_team[i][j]
print(Avg_ratings)
for j in range(len(data1_05to20)):
i = data1_05to20['year'][j]-2005
if data1_05to20['club'][j] in teams:
id = teams.index(data1_05to20['club'][j])
if data1_05to20['rating'][j] > MAX_ratings[i][id]:
MAX_ratings[i][id] = data1_05to20['rating'][j]
print(MAX_ratings)이후 각각 Avg_ratings와 MAX_ratings에 'None' 값이 존재할 경우 승률에서 했던 것과 마찬가지로 'None'이 아닌 값 중 평균으로 각각 다 변경해주었다. (이 과정 역시 생략해도 훈련/테스트 데이터를 만들 때 문제는 없다.)
for i in range(total_years):
for j in range(total_team_num):
if Avg_ratings[i][j] == 'None':
Avg_ratings[i][j] = sum([f[j] for f in Avg_ratings if f[j]!='None'])/len([f[j] for f in Avg_ratings if f[j]!='None'])
MAX_ratings[i][j] = sum([f[j] for f in MAX_ratings if f[j]!='None'])/len([f[j] for f in MAX_ratings if f[j]!='None'])
print(Avg_ratings)
print('None' in MAX_ratings)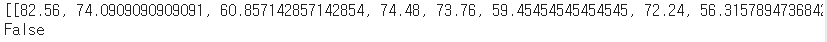
이후 21, 22, 23, 24년도 데이터셋도 각각 전처리해 주었다. 모든 파일이 각각 다른 사용자가 수집한 데이터였어서 각 컬럼의 이름과 데이터의 형식 등이 달랐지만 각각의 데이터셋에 맞게 코드를 변경하여 전처리를 해 주고 평균 평점과 최고 평점을 각각 Avg_ratings_21, Avg_ratings_22, Avg_ratings_23, Avg_ratings_24, MAX_ratings_21, MAX_ratings_22, MAX_ratings_23, MAX_ratings_24에 저장해 주었다. 이후 이를 CSV 파일로 만들기 위해 각각의 평균 평점과 최고 평점을 하나의 2차원 리스트(Avg_ratings, MAX_ratings)로 합쳐준 뒤 CSV 파일로 만들었다.
Avg_ratings.append(Avg_ratings_21)
Avg_ratings.append(Avg_ratings_22)
Avg_ratings.append(Avg_ratings_23)
Avg_ratings.append(Avg_ratings_24)
MAX_ratings.append(MAX_ratings_21)
MAX_ratings.append(MAX_ratings_22)
MAX_ratings.append(MAX_ratings_23)
MAX_ratings.append(MAX_ratings_24)
Teams = ['years']
Dataset_ratings = []
for i in range(total_team_num):
Teams.append(teams[i]+'_avg')
Teams.append(teams[i]+'_MAX')
for i in range(total_years+4):
l = [i+2005]
for j in range(total_team_num):
l.append(Avg_ratings[i][j])
l.append(MAX_ratings[i][j])
Dataset_ratings.append(l)
Dataset_ratings.insert(0,Teams)
print(Dataset_ratings)with open("/content/drive/MyDrive/footballAI/Dataset_ratings.csv", "w") as file:
writer = csv.writer(file)
writer.writerows(Dataset_ratings)아래는 이렇게 정리한 최종 CSV 파일의 일부이다.
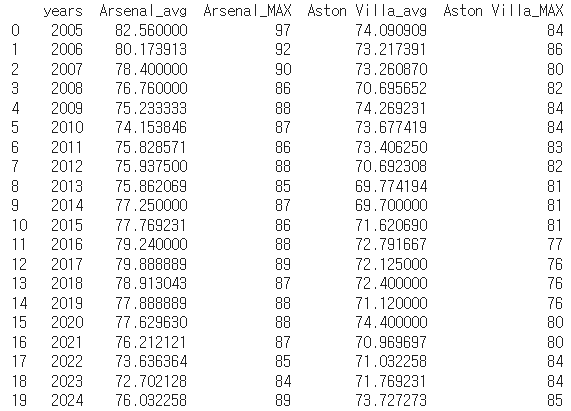
1-3. 최종 training dataset, test dataset
앞서 수집하여 만든 2개의 CSV과 각각의 경기 결과 데이터셋을 바탕으로 최종 training dataset과 test dataset을 만들어 보았다. 먼저, 각각의 training data와 test data의 칼럼은 'Year','Home','Away','Home_homewin','Away_awaywin','Home_draw','Away_draw','Home_avg','Home_MAX','Away_avg','Away_MAX'
이다. 각각의 feature의 의미를 순서대로 설명하면 (경기가 치뤄진 년도), (홈 팀), (어웨이 팀), (홈 팀의 홈 승률), (어웨이 팀의 어웨이 승률), (홈 팀의 무승부 확률), (어웨이 팀의 무승부 확률), (홈 팀의 평균 FIFA 평점), (홈 팀의 최대 FIFA 평점), (어웨이 팀의 평균 FIFA 평점), (어웨이 팀의 최대 FIFA 평점) 이다. training data의 training label의 칼럼은 'R'(Result-경기 결과) 하나이고, 이는 'D'(무승부), 'H'(홈 팀 승리), 'A'(어웨이 팀 승리) 3개 중 하나로 구성된다. 이를 고려해서 각각의 training data와 training label을 만들어보면 다음과 같다.
Final_train_data = [['Year','Home','Away','Home_homewin','Away_awaywin','Home_draw','Away_draw','Home_avg','Home_MAX','Away_avg','Away_MAX' ]]
Final_train_label = ['R']
for year in range(2005,2024):
for i in range(len(data)):
if data['Season_End_Year'][i] == year:
l = []
l.append(year)
l.append(data['Home'][i])
l.append(data['Away'][i])
home_idx = teams.index(data['Home'][i])+1
away_idx = teams.index(data['Away'][i])+1
l.append(rates_data.iloc[:,home_idx*3-2][year-1994])
l.append(rates_data.iloc[:,away_idx*3-1][year-1994])
l.append(rates_data.iloc[:,home_idx*3][year-1994])
l.append(rates_data.iloc[:,away_idx*3][year-1994])
l.append(fifa_data.iloc[:,home_idx*2-1][year-2005])
l.append(fifa_data.iloc[:,home_idx*2][year-2005])
l.append(fifa_data.iloc[:,away_idx*2-1][year-2005])
l.append(fifa_data.iloc[:,away_idx*2][year-2005])
Final_train_data.append(l)
Final_train_label.append(data['FTR'][i])
print(len(Final_train_data))
print(Final_train_data)
print(Final_train_label)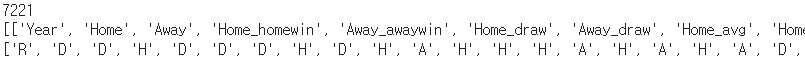
총 데이터의 개수는 7,221개였다. 이후 이 훈련 데이터 및 라벨을 각각 CSV 파일로 저장했다.
with open("/content/drive/MyDrive/footballAI/training_dataset.csv", "w") as file:
writer = csv.writer(file)
writer.writerows(Final_train_data)
with open("/content/drive/MyDrive/footballAI/training_labels.csv", "w") as file:
writer = csv.writer(file)
writer.writerows(Final_train_label)아래는 최종적으로 저장된 훈련 데이터 및 라벨의 일부이다.
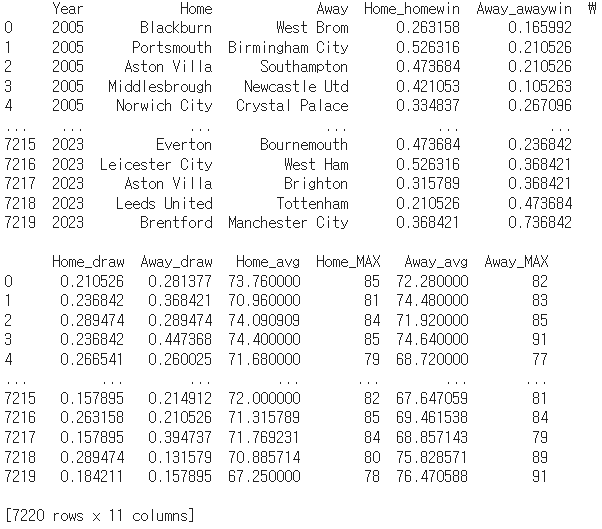

다음으로 테스트 데이터셋을 만들어보았다. 테스트 데이터셋에 사용될 승률과 평점은 각각 2023년에 계산된 승률과 FIFA24를 바탕으로 계산된 평점을 사용하면 되었으나 2024년의 경기의 결과를 아직 계산하지 않았다는 문제가 있었다. 따라서 마침 2024년의 프리미어리그 경기 일정이 몇 주 전에 종료되었기 때문에 이 경기 결과를 정리한 데이터셋을 수집한 뒤, 전처리를 거치기로 했다. 먼저 이렇게 수집한 데이터를 출력하면 다음과 같다.
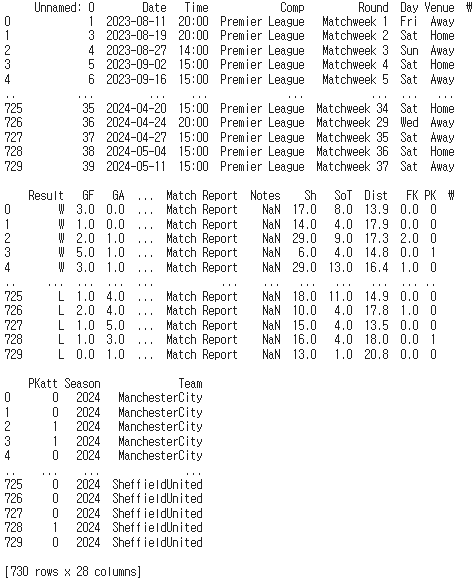
이 데이터도 마찬가지로 각각의 팀명을 검색하여 이전까지 저장해놓은 팀명으로 바꿔주는 팀명 수정 작업을 진행하였다. 또한 2024년의 경우 기존까지 프리미어리그에 한 번도 소속되어 있지 않았던 'Luton Town'이라는 팀이 프리미어리그에 소속되어있었기 때문에 데이터가 없는 'Luton Town'이 참여한 경기는 모두 제거를 해주었다. 2024년의 경기 데이터의 각각의 컬럼과 형식을 분석하고 이를 바탕으로 훈련 데이터셋, 라벨과 동일한 형식으로 테스트 데이터셋과 라벨을 구축해주면 다음과 같았다.
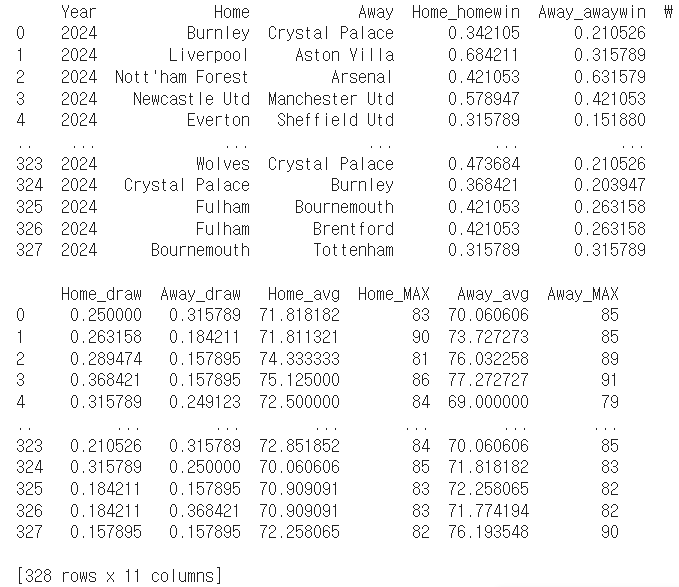
Final_test_data = [['Year','Home','Away','Home_homewin','Away_awaywin','Home_draw','Away_draw','Home_avg','Home_MAX','Away_avg','Away_MAX' ]]
Final_test_label = ['R']
temp = []
year = 2024
for i in range(len(test_data)):
if test_data['Team'][i] == 'LutonTown' or test_data['Opponent'][i] == 'LutonTown' or test_data['Team'][i] == 'Luton Town' or test_data['Opponent'][i] == 'Luton Town':
continue
l = []
l.append(year)
if test_data['Venue'][i] == 'Home':
l.append(test_data['Team'][i])
l.append(test_data['Opponent'][i])
home_idx = teams.index(test_data['Team'][i])+1
away_idx = teams.index(test_data['Opponent'][i])+1
else:
l.append(test_data['Opponent'][i])
l.append(test_data['Team'][i])
home_idx = teams.index(test_data['Opponent'][i])+1
away_idx = teams.index(test_data['Team'][i])+1
l.append(rates_data.iloc[:,home_idx*3-2][year-1994])
l.append(rates_data.iloc[:,away_idx*3-1][year-1994])
l.append(rates_data.iloc[:,home_idx*3][year-1994])
l.append(rates_data.iloc[:,away_idx*3][year-1994])
l.append(fifa_data.iloc[:,home_idx*2-1][year-2005])
l.append(fifa_data.iloc[:,home_idx*2][year-2005])
l.append(fifa_data.iloc[:,away_idx*2-1][year-2005])
l.append(fifa_data.iloc[:,away_idx*2][year-2005])
if test_data['Venue'][i] == 'Home' and test_data['Result'][i] == 'W':
l.append('H')
elif test_data['Venue'][i] == 'Home' and test_data['Result'][i] == 'L':
l.append('A')
elif test_data['Venue'][i] == 'Away' and test_data['Result'][i] == 'W':
l.append('A')
elif test_data['Venue'][i] == 'Away' and test_data['Result'][i] == 'L':
l.append('H')
elif test_data['Result'][i] == 'D':
l.append('D')
temp.append(l)
temp = list(set(map(tuple, temp)))
print(len(temp))
for i in range(len(temp)):
Final_test_data.append(list(temp[i][:len(temp[i])-1]))
Final_test_label.append(temp[i][-1])
print(Final_test_data)
print(Final_test_label)
출력 결과에서 볼 수 있듯이 총 테스트 데이터 수는 328개였다. 이후 이 데이터와 라벨을 각각 CSV 파일로 저장해두었다.
with open("/content/drive/MyDrive/footballAI/test_dataset.csv", "w") as file:
writer = csv.writer(file)
writer.writerows(Final_test_data)
with open("/content/drive/MyDrive/footballAI/test_labels.csv", "w") as file:
writer = csv.writer(file)
writer.writerows(Final_test_label)이렇게 만든 최종 테스트 데이터와 라벨의 일부는 다음과 같다.

2. 알고리즘 설계
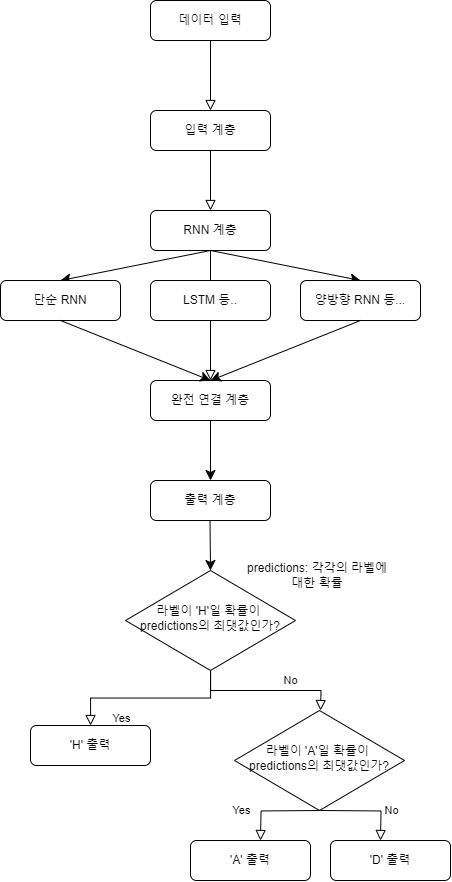
내가 개발할 인공지능의 알고리즘은 간단하게 "입력 → 모델 → 출력"으로 표시할 수 있다. 이때 입력 데이터는 [ 'Year','Home','Away','Home_homewin','Away_awaywin','Home_draw','Away_draw','Home_avg','Home_MAX','Away_avg','Away_MAX' ]의 feature를 가진 위에서 전처리한 데이터이다. 본 데이터는 시계열 데이터이므로 모델으로는 RNN 기반 모델(RNN, LSTM 등)을 사용할 것이다. 출력 데이터는 각각의 경기의 결과 'R' 만 출력하면 된다.
본 탐구에서 사용될 모델의 구조를 보다 자세하게 표현하면 4개의 계층으로 표현할 수 있다.
1. 입력 계층: 입력 데이터의 형태는 (배치 크기, 시퀀스 길이, feature 수) 이다. 이때, 배치 크기는 학습을 진행할 때 고려하게 되는 하이퍼파라미터로, 학습 과정에서 변경해보며 모델의 성능을 형성시켜볼 수 있다. 시퀀스 길이는 RNN 기반 모델에서 이용되는 특징으로 시계열 데이터 혹은 다른 순차적 데이터에서 연속된 요소의 개수와 같은 것을 말한다. 시퀀스 길이 역시 하나의 하이퍼파라미터처럼 작용할 수 있다. feature 수는 내가 사용하는 데이터의 특징 개수를 의미한다.
2. RNN 계층: 4월 과제에서 학습한 RNN/LSTM 계층이 들어가는 층이다. 본 계층을 통해 시계열 데이터의 특징 등을 효과적으로 모델이 학습할 수 있다. 본 RNN 계층에서는 유닛 수를 증가하거나 여러 RNN 계층을 쌓음으로써 모델의 복잡성을 증가시키거나(그러나 과적합 문제가 있다) 양방향 RNN을 사용하여 과거, 미래의 정보를 모두 사용하는 방법을 사용함으로써 모델의 성능을 향상시켜볼 수 있다. 과적합을 방지하고 모델의 일반적인 성능을 향상시키기 위해 드롭아웃을 적용시킬 수도 있다.
3. 완전 연결 계층: RNN 계층의 출력을 받아서 최종 예측을 위한 층이고, 활성화 함수는 'relu' 함수 등으로 설정할 수 있다.
4. 출력 계층: 최종 출력은 ('H','D','A') 3개 중 하나를 분류해내는 것이므로 출력 계층은 3개의 뉴런을 가지고 활성화 함수로는 softmax를 사용하면 된다. 손실 함수로는 'categorical_crossentropy' 등을 사용할 수 있다.
위 모델의 계층 정보를 바탕으로 본 탐구의 순서도를 간단히 구성하면 다음과 같다.
'정보과학융합탐구' 카테고리의 다른 글
| [정융탐] EPL 축구 경기 승부예측 AI 개발 프로젝트 (4) (1) | 2024.07.08 |
|---|---|
| [정융탐] EPL 축구 경기 승부예측 AI 개발 프로젝트 (3) (0) | 2024.06.23 |
| [정융탐] EPL 축구 경기 승부예측 AI 개발 프로젝트 (1) (2) | 2024.04.06 |
| [정융탐] EPL 축구 경기 승부예측 AI 개발 프로젝트 계획 (2) | 2024.03.23 |


